Dealing with Stuck Workers
2013-05-03
Occasionally Sidekiq users report workers that are “stuck” processing jobs for a long time. Usually this means that there are entries in the Workers page in the Web UI that linger for a long time. This post explains what you can do as a Sidekiq user to track down what is happening.
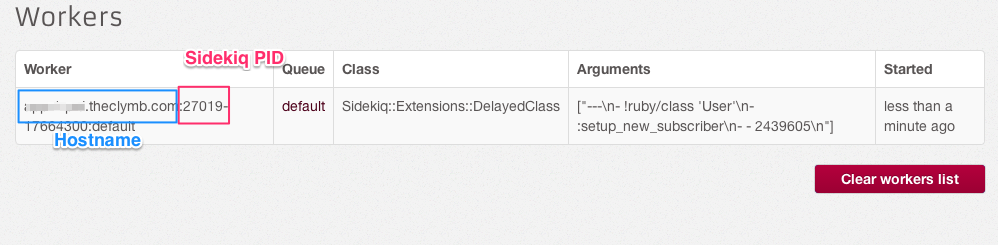
In the Web UI, the Workers page shows you a listing of all worker status entries in Redis. When a Worker starts processing a job, it adds a status entry to Redis. When the job is complete, the worker removes its entry from Redis. If you see one or more entries linger for much longer, this is a symptom of a bigger problem:
- The worker thread has locked up or is blocked by some other issue
- The Sidekiq process crashed
Log into the host noted in the list and look for the process with the PID. If the PID exists, the job is probably locked up somehow. Send the TTIN signal to Sidekiq to print a thread dump which should give you an idea where the job is stuck. Modify your code as necessary to fix the issue.
If the PID is gone, the process crashed, the worker dies and the status entry is orphaned in Redis. A Ruby process can crash due to bugs in either the Ruby VM itself or in a native extension your application is using.
Process crashes can be a serious problem: any jobs executing during the crash are lost. Unless the jobs are optional, you probably want to stop the job loss ASAP and here you have two solutions: spend time or money to stop the loss. If you have time you can find a core dump, use gdb to get a backtrace and start investigating the code at fault. Debugging a crashed process is a highly technical subject and not something that I can really cover adequately in a blog post.
Alternatively, you can buy Sidekiq Pro and use its reliable queueing feature. I spoke with a Sidekiq user at Railsconf whose processes were crashing and losing jobs. They jumped at the chance: rather than spending days tracking down the bug, they could live with a crash once or twice a day since Upstart would just restart the process and immediately resume the job. It’s not the ideal solution but it stopped the loss of jobs and put out the immediate fire: now they could debug the issue at their leisure rather than needing to fix it ASAP.