The Leaky Bucket rate limiter
2020-11-09
A few months ago, a customer asked if I could supply a “leaky bucket” rate limiter as part of Sidekiq Enterprise’s rate limiter suite. It took me a while to find the time and energy to work on it (my need to mentally escape the 2020 election eventually did the trick).
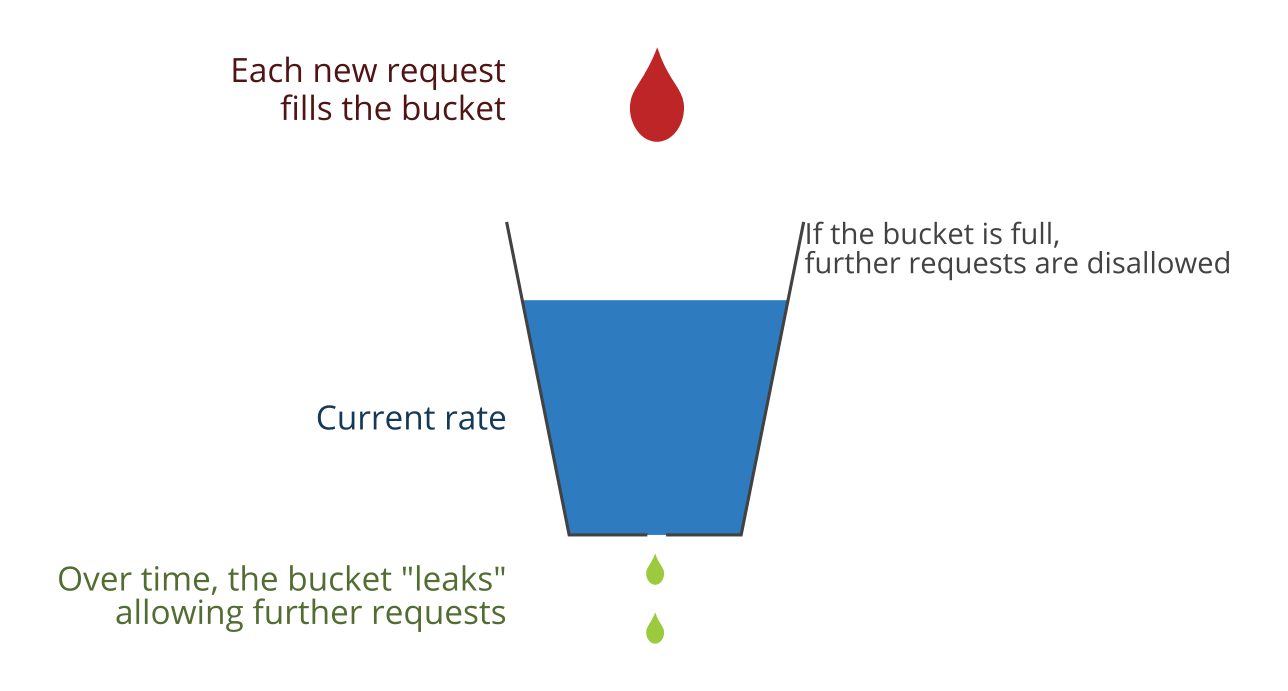
I went into this process knowing the basics of the leaky bucket algorithm but with no idea how to implement it. I’m not going to cover the algorithm here but check out that Wikipedia page if you want to learn the basics.
Research
First I did a GitHub search to look for existing implementations and read them to learn how they work. This way I can tie the abstract algorithm with specifics about how they are storing data, caveats they ran into, etc. It took me a few days to read, ponder and re-read the code to understand. Remember your secret weapons to understanding: sleeping and showering; that’s when you’ll figure stuff out.
I saw two different styles of implementation with Redis:
- Using ZSETs to store a timestamp of each successful call
- Using GET/SET with a counter and timestamp
The first suffers from a major issue: it’s O(n) with the bucket size. If you allow 10,000 calls every hour, the ZSET can hold up to 10,000 elements. I knew I didn’t want to go down that path.
The second is much better; it’s O(1) with the bucket size but unnecessarily old school Redis. Redis provides newer Hash commands which can perform all of the necessary logic while also keeping each limiter as one distinct, logical Hash element within Redis.
So that’s what I implemented: an O(1) storage, Hash-based limiter.
Implementation
You gotta buy Sidekiq Enterprise if you want the real deal but here’s the core of the implementation:
-- Decrement the drops based on the time which has passed since
-- the last call.
if drops > 0 and (lastcall + driprate) < current_time then
drops = drops - math.floor((current_time - lastcall) / driprate)
end
-- if the bucket has room for another drop, increment and return
if drops < size then
redis.call("hset", key, "lastcall", current_time, "drops", drops+1)
return nil
end
-- if the bucket is full, send the amount of time necessary to wait
-- for the next drop to drain.
return (lastcall + driprate) - current_time
Each time we call the limiter, we check to see if enough time has passed for 1 or more drips. If the bucket is full, we return the amount of time until the next drip.
Testing and Use
Of course I wrote some basic tests for the limiter but I wanted to take it further and implement a Rack-based limiter middleware. Here it is:
class LeakyLimiter
def initialize(app)
@app = app
end
def call(env)
remote_ip = env["REMOTE_ADDR"].tr(':', '_')
begin
limiter = Sidekiq::Limiter.leaky("ip-#{remote_ip}", 10, 10, wait_timeout: 0)
limiter.within_limit do
@app.call(env)
end
rescue Sidekiq::Limiter::OverLimit => ex
[429, {
"Content-Type" => "text/plain",
"X-Rate-Limited-For" => ex.limiter.next_drip.to_s,
}, ["Rate limited"]]
end
end
end
Note that this uses dynamic limiters, it creates a limiter for every single IP address that hits the webapp. For each IP address, we allow 10 calls every 10 seconds. If the IP has made more than 10 calls, the limiter will raise OverLimit and we’ll return them an HTTP 429 status code along with a header that indicates when the next drip happens (the drip is when the next call will succeed). Here it is in action:
[...eight previous calls snipped...]
> curl -i http://localhost:9292/api
HTTP/1.1 200 OK
Content-Length: 11
Hello world
> curl -i http://localhost:9292/api
HTTP/1.1 200 OK
Content-Length: 11
Hello world
> curl -i http://localhost:9292/api
HTTP/1.1 429 Too Many Requests
Content-Type: text/plain
X-Rate-Limited-For: 0.77912330627441
Content-Length: 12
Rate limited
> curl -i http://localhost:9292/api
HTTP/1.1 429 Too Many Requests
Content-Type: text/plain
X-Rate-Limited-For: 0.54235911369324
Content-Length: 12
Rate limited
This sample usage revealed an implementation detail that I decided to optimize: every request was making two round trips to Redis, one to create the limiter in Redis and one to check the rate limit. I refactored the code to remove the need to call Redis on creation; this will makes dynamic usecases like this example much faster. Every Rack request now requires only one call to Redis.
Benchmarks
Nothing is guaranteed in code until you have benchmarks to prove it,
right? I wrote a simple benchmark to test the three styles of time-based
limiters: leaky vs window vs bucket. It shows that the new leaky limiter
is twice as fast as the other two in this benchmark. This makes perfect
sense if you consider that the bucket and window limiters suffer from the
same issue explained above: they call Redis on new and within_limit
so they make twice as many network round trips as leaky.
user system total real
leaky 0.705626 0.155107 0.860733 ( 1.225562)
bucket 1.651114 0.418390 2.069504 ( 2.331178)
window 2.140379 0.590244 2.730623 ( 2.929512)
Conclusion
Writing this new feature was surprisingly fun and inspiring. The work spanned the entire engineering lifecycle:
- Research and understand an algorithm.
- Implement.
- Write tests, write benchmarks, write new usecase.
- Optimize based on that feedback.
- Write blog post and release.
I’ve uploaded the source code for the Rack example limiter and benchmark.
If you’re a Sidekiq Enterprise customer, run bundle up sidekiq-ent to pull in v2.2.0 or greater to try out the new leaky bucket limiter.
Open an issue if you have any questions or problems with it.